publications
2026
-
 VAIC: Vision-Guided Humanoid Agile Object Interaction Control via Decoupled CommandsIn ArXiv, 2026
VAIC: Vision-Guided Humanoid Agile Object Interaction Control via Decoupled CommandsIn ArXiv, 2026Humanoid robots hold immense potential for real-world assistance, yet agile interaction with objects in unstructured environments demands tightly coupled whole body coordination. Despite recent advancements, current controllers face a critical deployment gap. They rely heavily on dense reference trajectories and perfect state observability, which inherently limits physical generalization. We present Vision Guided Agile Interaction Control (VAIC), a unified framework that bridges this gap by operating exclusively on onboard depth, historical proprioception, and a decoupled user command interface. VAIC employs a two-stage distillation paradigm. First, a privileged teacher policy masters diverse interaction skills using precise object kinematics and exact environmental states. Second, a deployable student policy distills these capabilities by replacing full body tracking with velocity targets across multiple axes and an interaction indicator for each frame. The student utilizes a recurrent object adaptation module to implicitly infer unobservable object dynamics from raw depth streams and proprioception. Evaluations and real-world deployments on the humanoid robot demonstrate that a single VAIC policy successfully executes highly diverse dynamic tasks. These tasks include box carrying, cart interaction, and skateboarding, consistently outperforming baselines and advancing autonomous humanoid deployment.
@inproceedings{li2026vaic, title = {VAIC: Vision-Guided Humanoid Agile Object Interaction Control via Decoupled Commands}, author = {Li, Dongting and Wu, Qianyang and Chen, Xingyu and Li, Liang and Lin, Yuhang and Wu, Sikai and Zhang, Guoyao and Zhou, Mingliang and Xiang, Diyun and Zhang, Qiang and Xu, Renjing and Ma, Jianzhu}, booktitle = {ArXiv}, year = {2026}, } -
 HAIC: Humanoid Agile Object Interaction Control via Dynamics-Aware World ModelIn RSS, 2026
HAIC: Humanoid Agile Object Interaction Control via Dynamics-Aware World ModelIn RSS, 2026Humanoid robots exhibit significant potential for executing complex whole-body interaction tasks in unstructured environments. While recent advancements in Human-Object Interaction (HOI) have been substantial, prevailing methodologies predominantly address the manipulation of fully actuated objects, where the target is rigidly coupled to the robot’s end-effector and its state is strictly constrained by the robot’s kinematics. This paradigm neglects the pervasive class of underactuated objects characterized by independent dynamics and non-holonomic constraints, which pose significant control challenges due to complex coupling forces and frequent visual occlusions. To bridge this gap, we propose HAIC, a unified framework designed to enable robust interaction across a spectrum of object dynamics without reliance on external state estimation. Central to our approach is a novel dynamics predictor that infers high-order object states, specifically velocity and acceleration, solely from proprioceptive history. These predictions are explicitly projected onto static geometric priors to construct a spatially grounded representation of dynamic occupancy, allowing the policy to internalize collision boundaries and contact affordances in visual blind spots. We employ an asymmetric fine-tuning strategy where the world model continuously adapts to the student policy’s exploration, ensuring robust state estimation under distribution shifts. We evaluate our framework on a humanoid robot. Empirical results demonstrate that HAIC achieves high success rates in agile object interactions, including skateboarding, cart pushing, and cart pulling under various weight load conditions, by proactively compensating for inertial physical perturbations, while HAIC simultaneously masters multi-object interaction involving long-horizon tasks and carrying a box across composed terrain by predicting the dynamics of multiple objects.
@inproceedings{li2026haic, title = {HAIC: Humanoid Agile Object Interaction Control via Dynamics-Aware World Model}, author = {Li, Dongting and Chen, Xingyu and Wu, Qianyang and Chen, Bo and Wu, Sikai and Wu, Hanyu and Zhang, Guoyao and Li, Liang and Zhou, Mingliang and Xiang, Diyun and Ma, Jianzhu and Zhang, Qiang and Xu, Renjing}, booktitle = {RSS}, year = {2026}, }
2025
-
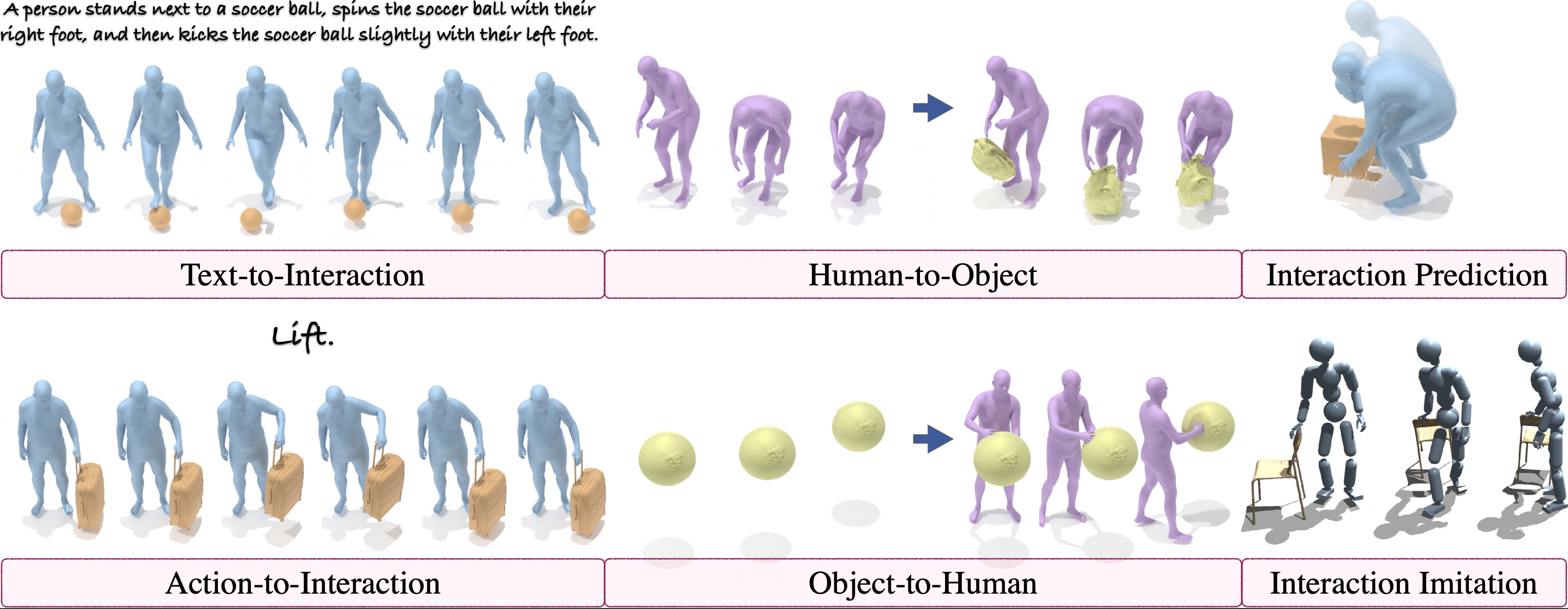 InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction GenerationIn CVPR, 2025
InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction GenerationIn CVPR, 2025While large-scale human motion capture datasets have advanced human motion generation, modeling and generating dynamic 3D human-object interactions (HOIs) remains challenging due to dataset limitations. These datasets often lack extensive, high-quality text-interaction pair data and exhibit artifacts such as contact penetration, floating, and incorrect hand motions. To address these issues, we introduce InterAct, a large-scale 3D HOI benchmark with key contributions in both dataset and methodology. First, we consolidate 21.81 hours of HOI data from diverse sources, standardizing and enriching them with detailed textual annotations. Second, we propose a unified optimization framework that enhances data quality by minimizing artifacts and restoring hand motions. Leveraging the insight of contact invariance, we preserve human-object relationships while introducing motion variations, thereby expanding the dataset to 30.70 hours. Third, we introduce six tasks to benchmark existing methods and develop a unified HOI generative model based on multi-task learning that achieves state-of-the-art results. Extensive experiments validate the utility of our dataset as a foundational resource for advancing 3D human-object interaction generation. The dataset will be publicly accessible to support further research in the field.
@inproceedings{xu2025interact, title = {InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction Generation}, author = {Xu, Sirui and Li, Dongting and Zhang, Yucheng and Xu, Xiyan and Long, Qi and Wang, Ziyin and Lu, Yunzhi and Dong, Shuchang and Jiang, Hezi and Gupta, Akshat and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {CVPR}, year = {2025}, }
2024
- Oral
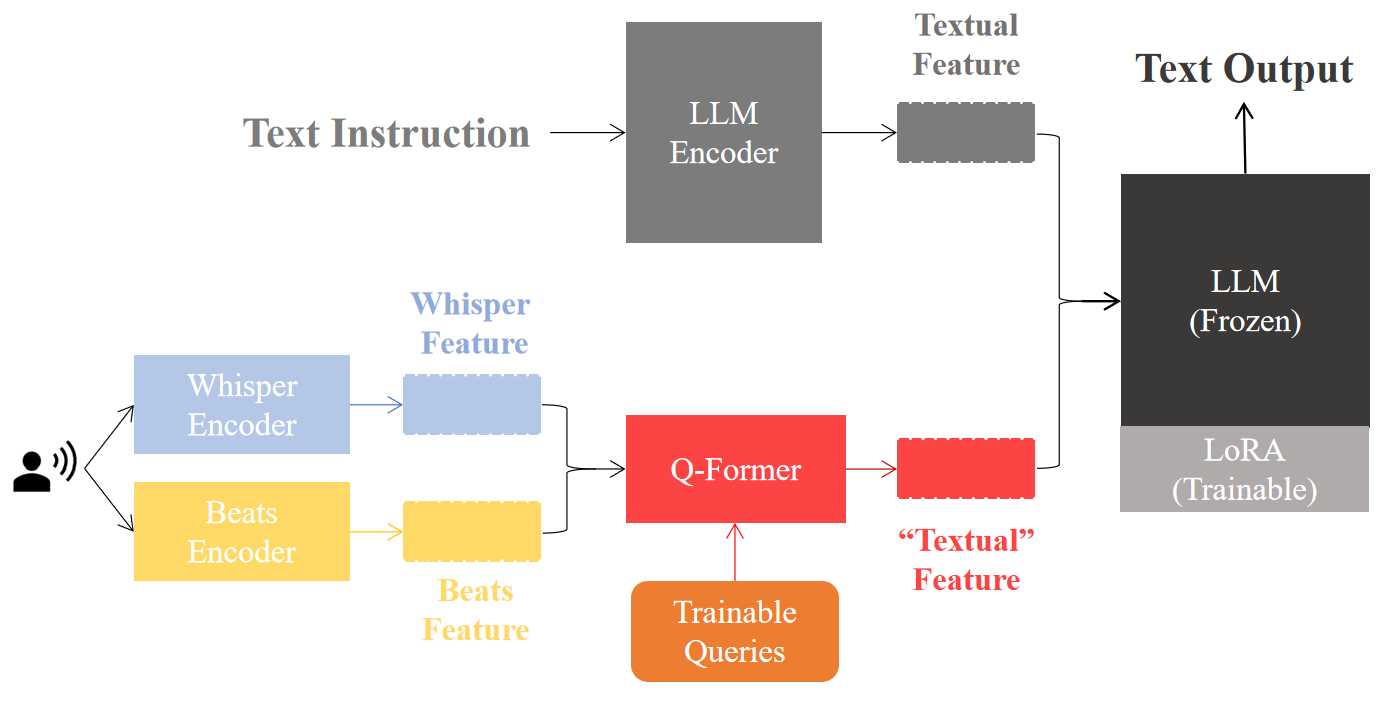 Audio-LLM: Activating the Capabilities of Large Language Models to Comprehend Audio DataDongting Li, Chenchong Tang, and Han LiuIn Advances in Neural Networks – ISNN, 2024
Audio-LLM: Activating the Capabilities of Large Language Models to Comprehend Audio DataDongting Li, Chenchong Tang, and Han LiuIn Advances in Neural Networks – ISNN, 2024We introduce Audio-LLM, a large language model that improves audio question-answering (AQA) systems and activates the capabilities of large language models to comprehend audio data. Our task entails introducing an encoding method that effectively transforms audio data into embedded representations, enabling LLMs to comprehend and process the information contained within the audio. By undergoing a series of fine-tuning stages, we establish alignment between audio and text, allowing LLMs to leverage both auditory and textual prompts. This alignment enables the model to achieve remarkable performance in automatic speech recognition (ASR), emotion recognition (ER), English-to-Chinese translation (En2Zh), music captioning (MC), and so on, demonstrating its versatility across various downstream applications. In addition, our model can be trained efficiently. During training, we only need to update approximately 20 million parameters, which represent about 0.27% of the entire Audio-LLM model. Furthermore, the discussion part highlights the model’s adaptability to zero-shot tasks, positioning Audio-LLM as a significant advancement with far-reaching implications for generalized hearing AI.
@inproceedings{li2024audiollm, author = {Li, Dongting and Tang, Chenchong and Liu, Han}, title = {Audio-LLM: Activating the Capabilities of Large Language Models to Comprehend Audio Data}, booktitle = {Advances in Neural Networks -- ISNN}, year = {2024}, }